Data
The dataset to be released is the road images, including damaged parts. The images have been collected from the following three countries: Japan, India, and Czech.
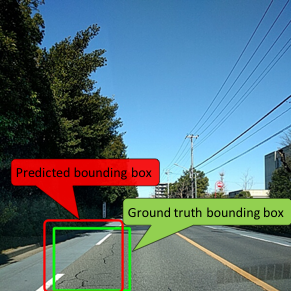
The damage information is provided as the coordinates of the bounding box and a label depicting the type of damage associated with the box.
The dataset is divided into three parts: Training, Test 1, Test 2, out of which the first two will be released soon after the competition starts, and the last one will be released in September.
The dataset is publicly available on the website (https://github.com/sekilab/RoadDamageDetector). There are no privacy concerns regarding the data: all the faces and license plates have been blurred by visual inspection. The number of images is presented in the table below.
Schedule of Data Release:
- Release of Training Dataset - May 10th
- Release Test1 – May 15th
- Release Test2 – Sept 10th
The data collection methodology, study area and other information for the India-Japan-Czech dataset are provided in our research paper entitled [Transfer Learning-based Road Damage Detection for Multiple Countries].
If you use or find our datasets and/or article useful, please cite.
@misc{arya2020transfer,
title={Transfer Learning-based Road Damage Detection for Multiple Countries},
author={Deeksha Arya and Hiroya Maeda and Sanjay Kumar Ghosh and Durga Toshniwal and Alexander Mraz and Takehiro Kashiyama and Yoshihide Sekimoto},
year={2020},
eprint={2008.13101},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Evaluation
The Evaluation Metrics:
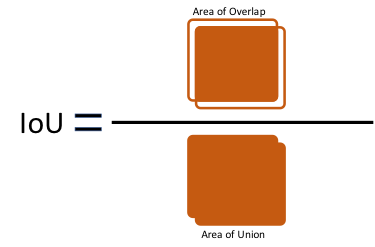
The results are evaluated by "F-Measure." The prediction is considered to be correct only when IoU (Intersection over Union, see Fig.1) is 0.5 or more, and the predicted label and the ground truth label match. Dividing the area of overlap by the area of union yields intersection over union (Fig.2). The evaluation metric for this competition is comparing with ground truth Mean F1-Score. The F1 score, commonly used in information retrieval, measures accuracy using the statistics precision p and recall r. Precision is the ratio of true positives (tp) to all predicted positives (tp + fp). Recall is the ratio of true positives to all actual positives (tp + fn). The F1 score is given by:
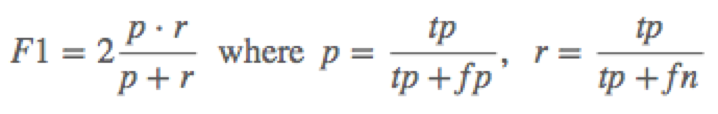
The F1 metric weights recall and precision equally, and a good retrieval algorithm will maximize both precision and recall simultaneously. Thus, moderately good performance on both will be favored over excellent performance on one and poor performance on the other. The average evaluation result for the three-country dataset will be measured, and the team providing the highest F1-score will win the competition.